
Kavyashree Byalya
Nanjegowda
KI Software Engineer | M.Sc. Digital Engineering
Ich bin ein auf KI/ML spezialisierter Softwareentwickler mit mehr als vier Jahren Berufserfahrung in den Bereichen Automatisierung, agentenbasierte Systeme und produktionsreife technische Lösungen.Ich absolviere derzeit einen Master of Science in Digital Engineering an der Otto-von-Guericke-Universität Magdeburg mit den Schwerpunkten maschinelles Lernen, Data Engineering und intelligente Systeme.In meiner derzeitigen Position als Werkstudent bin ich in den Bereichen Softwareentwicklung und Qualitätssicherung tätig und beschäftige mich mit der Konzeption und Integration von KI-Funktionen, insbesondere KI-gesteuerten Multi-Agenten-Workflows, um die Zuverlässigkeit und Wirkung von Produkten zu verbessern.Zuvor war ich fast drei Jahre lang als Softwareentwickler bei Accenture tätig, wo ich meine Erfahrungen in den Bereichen Softwareentwicklung und Qualitätssicherung durch die Entwicklung von Funktionen, die Unterstützung von Produktionsreleases und Eskalationen sowie die funktionsübergreifende Zusammenarbeit in agilen Release-Zyklen vertiefen konnte.Aktuell suche ich eine Position als AI Engineer, Machine Learning Engineer oder AI Automation Engineer. Zudem bin ich offen für Data-Scientist-Rollen mit Fokus auf der praxisnahen Implementierung von KI-Lösungen in realen Anwendungsszenarien.
FÄHIGKEITEN
KI & Agentensysteme: RAG, LangChain, LangGraph, CrewAI, n8nMachine Learning & Deep Learning: Scikit-learn, PyTorch, TensorFlow, MLflowProgrammiersprachen: Python, Java, TypeScript, JavaScriptFrontend: React, Material UI, StorybookBackend & APIs: FastAPI, REST, Swagger, DockerDatenbanken: PostgreSQL, SQL/MySQL, SQL; Vektordatenbanken: ChromaDB, FAISSTesting & Qualitätssicherung: Playwright, Jest, JMeterSprachen: Deutsch (B1), Englisch (C1)

PROJEKTE
Diese Projekte zeigen meine Arbeit in den Bereichen KI/ML, Data Analytics und Software Engineering, in denen ich Ideen in zuverlässige, funktionierende Systeme überführe. Ich setze Projekte ganzheitlich um – von der Problemdefinition und Datenaufbereitung über Modellierung und Evaluation bis hin zur Bereitstellung in Form interaktiver Dashboards oder implementierter Prototypen. Dabei stehen reproduzierbare ML-Workflows, erklärbare Ergebnisse und eine saubere, strukturierte Umsetzung mit Fokus auf realen Mehrwert im Mittelpunkt. Jede Lösung wird zur gezielten Lösung eines konkreten Problems entwickelt, datenbasiert validiert und auf Klarheit sowie Benutzerfreundlichkeit ausgelegt.
Vielen Dank, dass Sie sich die Zeit genommen haben, mein Portfolio zu besuchen!
Wenn Sie der Meinung sind, dass ich gut in Ihr Team passe, freue ich mich über Ihre Kontaktaufnahme. Sie können mich per E-Mail oder über LinkedIn erreichen oder das untenstehende Formular nutzen.
© Untitled. All rights reserved.
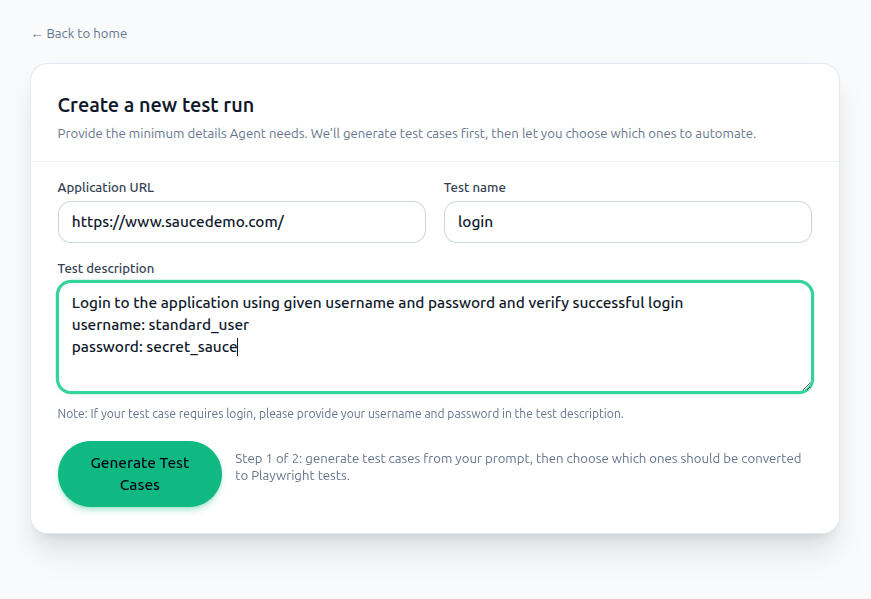
AI-Powered Test Automation Agent
Entwickelte ein Multi-Agenten-System, das strukturierte Testfälle und ausführbare Playwright-Skripte direkt aus natürlichen Sprachbefehlen generiert. Benutzer geben über eine React-basierte Web-Benutzeroberfläche die URL der Ziel-App und eine Testbeschreibung ein, wodurch eine crewAI-Agenten-Pipeline ausgelöst wird, die die App untersucht, Testfälle generiert, Benutzern die Auswahl bestimmter Szenarien ermöglicht, ein TypeScript Playwright-Testskript erstellt und fehlgeschlagene Tests bis zu dreimal automatisch korrigiert.Tools: Python, crewAI, FastAPI, OpenAI API, Playwright, Playwright MCP, React, TypeScript, Vite, Tailwind CSS
MBSE Requirements Automation with LLM
Entwicklung eines natürlichsprachlich gesteuerten Systems zur Unterstützung der Automatisierung der Anforderungsmodellierung im Model-Based Systems Engineering (MBSE) für Fertigungssysteme. Konzeption einer intuitiven Streamlit-Oberfläche, über die Fachexperten Systembeschreibungen in natürlicher Sprache eingeben können. Einsatz der Perplexity API zur Umwandlung unstrukturierter Texte in strukturierte JSON-Daten, die anschließend zur Generierung von SysML-Anforderungsdiagrammen mit Gaphor verwendet wurden.Tools: Python, Streamlit, Perplexity API, Gaphor


Feature Importance Analysis for Energy Forecasting in CNC Machines
Implementierung fortgeschrittener Feature-Attributionsmethoden zur Identifikation zentraler Einflussfaktoren des Energieverbrauchs in CNC-Maschinenprozessen. Vergleich gradientenbasierter (Integrated Gradients), entfernungsgestützter (Permutation Importance), modellbasierter (WINIT) sowie lokaler Erklärungsverfahren (LIME) über verschiedene Modelle hinweg, darunter LSTM, GRU, XGBoost und Random Forest. Visualisierung und Interpretation der Merkmalsrelevanz in Zeitreihendaten zur Ableitung praxisnaher Maßnahmen zur Energieoptimierung.Tools: Python, Scikit-learn, NumPy, Pandas, Streamlit, TensorFlow
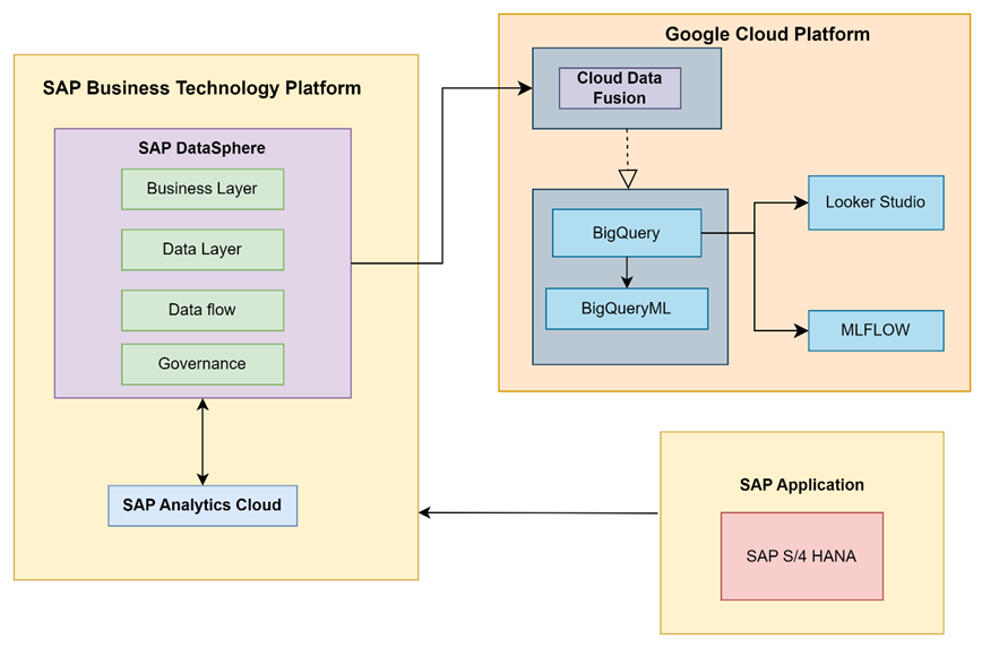
Cloud-Based Machine Learning Pipeline for Market Forecasting and Analysis
Entwicklung einer durchgängigen, cloudbasierten Machine-Learning-Pipeline zur Marktsegmentierung und Nachfrageprognose für Mobilitätsprodukte. Unternehmensdaten aus SAP Datasphere wurden in BigQuery integriert; Datenaufbereitung und Modellierung erfolgten mit BigQuery ML unter Einsatz von K-Means zur Segmentierung sowie ARIMA_PLUS zur Prognose von Absatz und Materialbedarfen. Zur Sicherstellung reproduzierbarer Modellentwicklung wurden Experimente und Trainingsläufe mit MLflow versioniert und verwaltet. Die Ergebnisse wurden in interaktiven Dashboards in Google Cloud Looker Studio visualisiert, um Prognosen transparent darzustellen und datenbasierte Geschäftsentscheidungen zu unterstützen.Tools: Google Cloud Platform (BigQuery, BigQuery ML, Looker Studio), SAP Datasphere, MLflow, Python, SQL
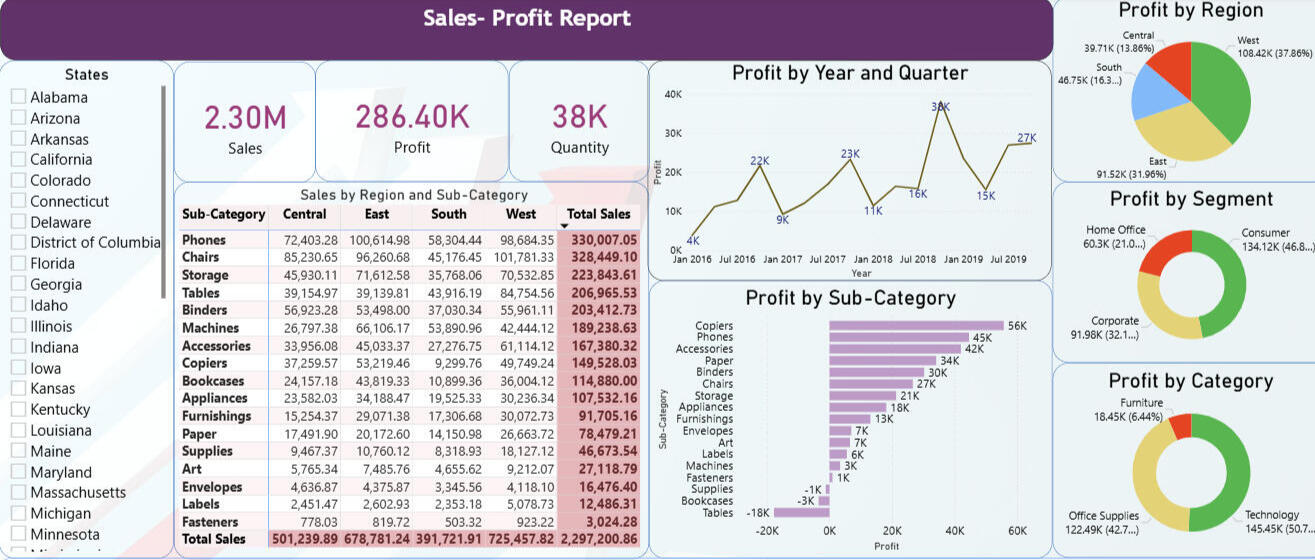
Sales and Profit Dashboard in Power BI
Entwicklung eines interaktiven Power-BI-Reports auf Basis eines mehrjährigen US-Superstore-Datensatzes zur Analyse von Umsatz und Profitabilität nach Region, Kundensegment und Produktkategorie. Ermöglichung von Self-Service-Analysen durch den Einsatz von KPI-Karten, Slicern, Drilldowns und Zeitreihenansichten, um Gewinnreiber sowie verlustbringende Bereiche transparent zu identifizieren.Tools: Power BI Desktop, DAX, Power Query, Excel (Datensatz)
Interactive 3D Rotary Calciner Simulation for Process Engineering Education
Entwicklung von „Calciner Quest“, einer Windows-basierten Unity-3D-Lernanwendung, in Zusammenarbeit mit Studierenden der Chemie- und Energietechnik zur Visualisierung eines internen Drehrohrofens und zur Simulation zentraler Prozessabläufe mittels geführter Szenen und interaktiver 3D-Erkundung. Implementierung einer wartbaren Softwarearchitektur mit klarer Dokumentation unter Verwendung der Entwurfsmuster Singleton, Entity-Component-System (ECS) und Decorator zur strukturierten Steuerung von Dialogen, Audio, Animationen und Kameraführung.Tools: Unity 3D, C#, Blender, SolidWorks, AutoCAD

MBSE Requirements Automation with LLM
Projektübersicht
Dieses Projekt wurde in Zusammenarbeit mit dem Lehrstuhl für Systems Engineering der Otto-von-Guericke-Universität Magdeburg im Rahmen meines Masterstudiums entwickelt. Es implementiert einen natürlichsprachlich gesteuerten Assistenten zur Automatisierung der Anforderungsmodellierung im Model-Based Systems Engineering (MBSE) für Fertigungssysteme. Fachexperten können Systemanforderungen in natürlicher Sprache formulieren, woraufhin das System diese in ein strukturiertes Modell überführt, das als SysML-Anforderungsdiagramm in Gaphor geöffnet und weiterbearbeitet werden kann.Problemstellung
Anforderungen in der Fertigung werden häufig informell in natürlicher Sprache durch Domänenexperten erfasst. Die Überführung in formale SysML-Anforderungsmodelle bringt jedoch mehrere Herausforderungen mit sich:
1. Der Prozess ist zeitaufwendig und erfordert fundierte Kenntnisse in MBSE-Tools, was eine Zugangshürde für Nicht-Spezialisten darstellt.
2. Die manuelle Diagrammerstellung in spezialisierten Modellierungswerkzeugen verlangsamt frühe Phasen der Systementwicklung und Iteration.
3. Die Pflege und Aktualisierung von Anforderungssätzen über den gesamten Projektlebenszyklus hinweg erfordert effiziente Workflows, die Automatisierung und manuelle Kontrolle sinnvoll kombinieren.Lösung & Implementierung
Entwicklung einer Streamlit-Anwendung mit mehreren Workflows, die drei unterschiedliche Wege zur Erstellung und Verwaltung von Anforderungsmodellen bietet:
1. Direkteingabe-Workflow: Nutzer definieren bis zu 20 Anforderungen mit Titel und Beschreibung. Das System generiert daraus eine herunterladbare .gaphor-Datei, die unmittelbar weiterverwendet werden kann. Dies erleichtert insbesondere Anwendern ohne Modellierungstool-Erfahrung den Einstieg.
2. Workflow für natürlichsprachliche Verarbeitung: Nutzer beschreiben Anforderungen konversationell. Das Perplexity-AI-Backend analysiert die Eingaben und erzeugt strukturierte SysML-Anforderungen auf Konzeptebene, die als standardisierte Diagramme exportiert werden. Dadurch wird technische Komplexität abstrahiert.
3. Modellaktualisierungs-Workflow: Bestehende .gaphor-Dateien können hochgeladen und über eine intuitive Oberfläche mittels Create, Read, Update und DeleteOperationen bearbeitet werden. Dies ermöglicht iterative Anpassungen ohne direkte manuelle Diagrammbearbeitung.Die Backend-Architektur gewährleistet eine nahtlose Integration mit Gaphor durch gezielte XML-Generierung, LLM-Prompt-Design gemäß ISO 15288 und MBSE-Best Practices sowie eine strukturierte JSON-Zwischenrepräsentation zur Sicherstellung von Konsistenz und Nachvollziehbarkeit.Mehrwert & Nutzen
1. Deutliche Reduzierung der technischen Einstiegshürde für die Erstellung standardkonformer MBSE-Diagramme und damit Demokratisierung des Requirements Engineering für unterschiedliche Nutzergruppen.
2. KI-gestützte Automatisierung beschleunigt die frühe Anforderungsspezifikation, bewahrt strukturelle Integrität und reduziert manuelle Modellierungsfehler.
3. Native Unterstützung des Gaphor-Dateiformats ermöglicht eine reibungslose Integration in bestehende MBSE-Workflows und nachgelagerte Entwicklungsprozesse.Verwendung der Anwendung
1. Öffnen Sie das Projekt-Repository und folgen Sie den Anweisungen in der README-Datei, um die Streamlit-Anwendung lokal zu starten.
2.Wählen Sie einen Workflow:
- Direkteingabe: Anforderungen manuell definieren und Modelldatei herunterladen.
- KI-Generierung: Anforderungen in natürlicher Sprache beschreiben und automatisch ein SysML-Diagramm erzeugen lassen.
- Modellbearbeitung: Bestehende Datei hochladen und Anforderungen hinzufügen, ändern oder löschen.
3. Download: Laden Sie die generierte oder aktualisierte .gaphor-Datei herunter.
4. Visualisierung: Öffnen Sie die Datei in Gaphor, um das Anforderungsdiagramm anzuzeigen und weiterzuentwickeln.Installation von Gaphor: Download unter https://gaphor.org/download/ für Windows oder macOS.Zukünftige Erweiterungen
Das Konzept kann über Anforderungen auf Konzeptebene hinaus erweitert werden, um zusätzliche SysML-Artefakte wie Aktivitäts- und Strukturdiagramme zu generieren und gleichzeitig die Rückverfolgbarkeit zwischen Anforderungen, Funktionen und Komponenten sicherzustellen. Darüber hinaus sind mehrsprachige Eingaben sowie erweiterte Exportformate denkbar, um weitere MBSE-Tools und zukünftige Standards wie SysML v2 zu unterstützen.
Feature Importance in Time Series For Energy Consumption in CNC Machine
Projektübersicht
Dieses Projekt wurde in Zusammenarbeit mit der Forschungsgruppe „Autonomous Multi-sensor Systems (AMS)“ an der Otto-von-Guericke-Universität Magdeburg im Rahmen eines AMS-Laborprojekts durchgeführt. Im Fokus stand die Analyse der Merkmalswichtigkeit in Zeitreihendaten zur Energieverbrauchsprognose von CNC-Maschinen. Grundlage bildeten reale CNC-Sensorprotokolle sowie mehrere Machine-Learning-Modelle in Kombination mit Explainability-Methoden – Integrated Gradients (IG), WINIT, LIME und Permutation Importance, um die einflussreichsten Prozess- und Sensorsignale zu identifizieren und energieeffiziente Fertigungsprozesse zu unterstützen.Problemstellung
1. Welche Prozess und Sensorvariablen beeinflussen den Energieverbrauch von CNC-Maschinen unter unterschiedlichen Bearbeitungsbedingungen am stärksten?
2. Wie unterscheiden sich Feature-Importance-Methoden hinsichtlich Genauigkeit, Laufzeit und Aussagekraft der Erklärungen für industrielle Zeitreihendaten?
3. Wie können die Ergebnisse über eine interaktive Benutzeroberfläche zugänglich gemacht werden, sodass Ingenieure Erklärungen szenarienübergreifend analysieren können?Vorgehensweise und Methodik1. Datensatzaufbereitung und Vorverarbeitung
- Verwendung von vier realen Zeitreihendatensätzen einer DMC2-CNC-Maschine: DMC2ALCP1, DMC2ALCP2, DMC2SCP1, DMC2SCP2 (Aluminium/Stahl × CP1/CP2).
- Entfernung irrelevanter oder konstanter Spalten (z. B. CYCLE, ADBD0, ungenutzte POWER-Kanäle).
- Ausschluss von 28 Spalten mit fehlenden Werten (NaNs).
- Eliminierung inaktiver Achsmerkmale; Beibehaltung von 52 relevanten Merkmalen in Bezug auf aktive Achsen und Spindel.
- Standardisierung der Eingabedaten und Normalisierung der Zielvariable zur Stabilisierung des Trainings.
- Durchführung zweier experimenteller Einstellungen: mit und ohne korrelationsbasierte Filterung (Entfernung hoch korrelierter Merkmale), um Redundanzeffekte zu analysieren. Sämtliche Modellierungs- und Explainability-Durchläufe wurden offline ausgeführt; Metriken, Visualisierungen und Top-Merkmale wurden gespeichert und später in der Anwendung bereitgestellt.2. Implementierte Feature-Importance-Methoden
- Integrated Gradients (IG): Gradientenbasierte Attributionen für differenzierbare Modelle (angewendet auf FNN/LSTM).
- WINIT: Fensterbasierte Zeitreihen-Attribution zur Erfassung zeitlicher und verzögerter Effekte (angewendet mit LSTM und explorativ mit XGBoost).
- LIME: Lokale Surrogat-Erklärungen, evaluiert mit LSTM, Random Forest und XGBoost.
- Permutation Importance (PI): Shuffle-basierte Wichtigkeitsmessung anhand des Performanceverlusts, eingesetzt bei baumbasierten Modellen (Decision Tree, Random Forest).3. Evaluation und Vergleich
Vergleich der Methoden anhand von Testverlust, Ausführungszeit sowie Interpretierbarkeit und Stabilität der ranghöchsten Merkmale über verschiedene Szenarien hinweg.4. Streamlit-Anwendung
- Integration der Experimentergebnisse in ein interaktives Streamlit-Dashboard. Die Benutzeroberfläche ermöglicht Vergleiche zwischen Datensatzszenarien und Explainability-Methoden, einschließlich Visualisierungen und gerankter Merkmalslisten.
- Nutzer können eine Methode (IG/WINIT/LIME/PI) sowie ein Szenario (Material/Programm) auswählen und anschließend Merkmalsranglisten sowie Performance-Kennzahlen direkt analysieren.Zentrale Erkenntnisse
1. Merkmalsranglisten variieren je nach Szenario und Methode; daher ist der Vergleich mehrerer Erklärungsansätze für industrielle Datensätze essenziell.
2. Integrated Gradients in Kombination mit einem FNN und korrelationsbasierter Filterung zeigte über alle Datensätze hinweg ein ausgewogenes Verhältnis zwischen Genauigkeit, Laufzeit und Interpretierbarkeit.
3. Signale im Zusammenhang mit Drehmoment/Last sowie Regelabweichungen traten konsistent als einflussreiche Treiber von Energieverbrauchsmustern auf.Verwendung der Anwendung
1. Öffnen Sie das Dashboard über den bereitgestellten link.
2. Wählen Sie eine Methode (IG / WINIT / LIME / Permutation) sowie ein Datensatzszenario (Material/Programm).
3. Analysieren Sie die gerankten Merkmale und vergleichen Sie Zielkonflikte anhand von Testverlust und Ausführungszeit.Zukünftige Erweiterungen
Derzeit stellt die Anwendung vorab berechnete Feature-Importance-Ergebnisse dar. Für den industriellen Einsatz kann die Architektur jedoch um eine CI/CD-Pipeline und Datenupload-Funktionalität erweitert werden. Dadurch ließen sich Vorverarbeitung, Modellbewertung und Erklärungsberechnung automatisieren, sodass sich das Dashboard von einem statischen Analysewerkzeug zu einer skalierbaren, kontinuierlich aktualisierten Analytics-Plattform weiterentwickeln kann.
Cloud-Based Machine Learning Pipeline for Market Forecasting and Analysis
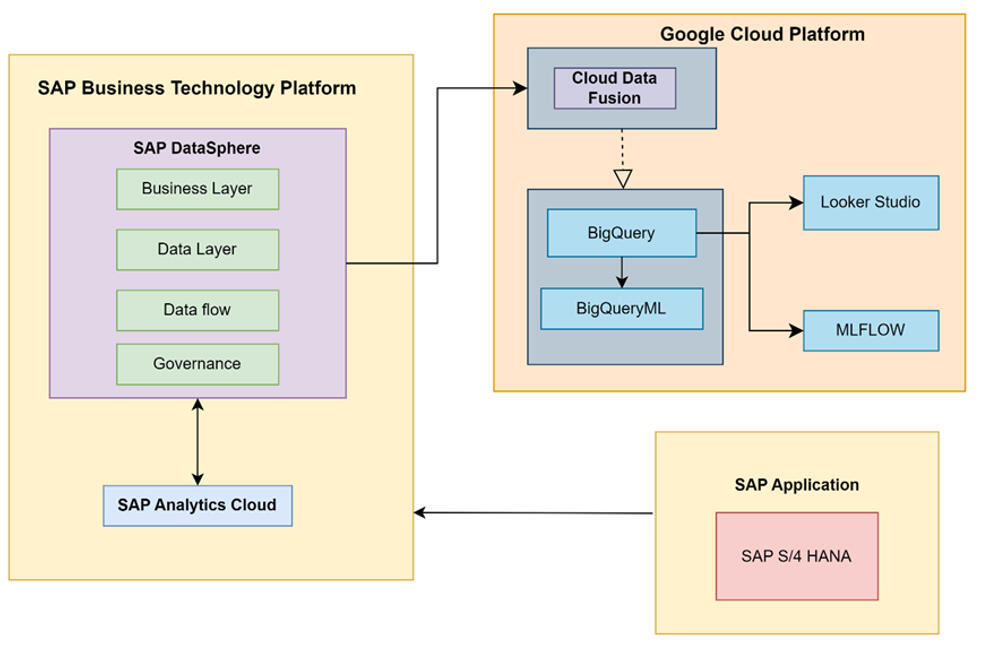
Projektübersicht
Dieses Projekt wurde im Rahmen der Lehrveranstaltung „VLBA – System Architectures“ an der Otto-von-Guericke-Universität Magdeburg (OvGU) durchgeführt. Ziel war der Aufbau einer durchgängigen, cloudbasierten Machine-Learning-Pipeline für Analysen im Bereich Fertigung und Produktdistribution. Auf Basis realer Unternehmensdaten aus SAP Datasphere wurde eine umfassende Prognoselösung entwickelt, die geografische Kundensegmentierung, Absatzprognosen sowie Materialbedarfsplanung integriert, um strategische Geschäftsentscheidungen für einen globalen Hersteller von Mobilitätsprodukten zu unterstützen.Problemstellung
1. Welche geografischen Märkte weisen die höchste Kundendichte und das größte Umsatzpotenzial auf, um strategische Ressourcenallokation und Marketinginvestitionen gezielt zu steuern?
2. Wie entwickeln sich die erwarteten Absatzmengen der Produkte in den nächsten 5–7 Jahren, um eine proaktive Produktionsplanung und reduzierte Lagerhaltungskosten zu ermöglichen?
3. Welche Materialmengen werden benötigt, um die prognostizierte Nachfrage zu decken und Beschaffungsstrategien zu optimieren sowie Lieferengpässe zu vermeiden?
4. Wie können diese Erkenntnisse über interaktive Dashboards bereitgestellt werden, sodass Entscheidungsträger Szenarien explorieren und datenbasierte Entscheidungen in Echtzeit treffen können?Vorgehensweise und Methodik
1. Datenintegration und Architekturaufbau
- Aufbau einer Cloud-Infrastruktur zur Anbindung von SAP Datasphere an die Google Cloud Platform unter Nutzung von Cloud Data Fusion für automatisierte Datentransfers.
- Einrichtung eines MLflow-Tracking-Servers auf GCP zur Verwaltung von Experimenten und Modellversionen.2. Datenaufbereitung und -bereinigung
- Extraktion von über 10 Jahren historischer Daten (über 50.000 Datensätze) aus SAP Datasphere zu Kunden, Aufträgen, Produkten und Materialien.
- Behebung von Datenqualitätsproblemen durch Imputation fehlender Werte und Korrektur von Kodierungsfehlern.
- Anreicherung der Kundendaten mit geografischen Koordinaten (Breiten- und Längengrad) mittels Google Maps Geocoding API.3. Geografische Marktsegmentierung
Anwendung von K-Means-Clustering auf Kundengeokoordinaten zur Identifikation klar abgegrenzter Marktsegmente und Analyse zugehöriger Umsatzmuster.4. Absatzprognose mit ARIMAPLUS
- Entwicklung von ARIMAPLUS-Zeitreihenmodellen in BigQuery ML auf Basis europäischer Marktdaten.
- Erstellung einer 7-Jahres-Prognose sowie spezifischer Jahresvorhersagen zur Unterstützung der Produktionsplanung.5. Materialbedarfsprognose
- Ableitung des Materialbedarfs aus den Absatzprognosen.
- Entwicklung separater ARIMA_PLUS-Modelle zur Prognose des Materialverbrauchs.6. MLflow-Orchestrierung
- Protokollierung sämtlicher Experimente, Modelle, Prognosen und Evaluationsmetriken in MLflow zur Sicherstellung der Reproduzierbarkeit.
- Nachverfolgung von Parametern (Länder, Zeiträume, Modelle) sowie Metriken (AIC, Varianz, Konfidenzintervalle).7. Entwicklung interaktiver Dashboards
- Erstellung von drei Looker-Studio-Dashboards: Geografische Segmentierung (Karten, Umsatzdiagramme, Produktverteilung),
Absatzprognosen (Trendanalysen, Marktanteile),
Materialbedarfsplanung (Detailaufschlüsselung, 5-Jahres-Nachfrageprognose)
- Ermöglichung interaktiver Szenarioanalysen für Geschäftsanwender.Zentrale Erkenntnisse
1. Die Integration von Unternehmenssystemen (SAP) mit Cloud-Analytics-Plattformen (GCP) schafft eine skalierbare Grundlage für End-to-End-ML-Pipelines – von der Datenintegration über Prognosemodelle bis hin zur interaktiven Visualisierung für fundierte Fertigungsentscheidungen.
2. Geografisches Clustering unterstützt eine gezielte Ressourcenallokation und marktindividuelle Strategien mit hohem geschäftlichem Mehrwert.
3. Produktbasierte Prognosen identifizierten divergierende Trends: Wachstumsstarke Produkte erfordern Kapazitätserweiterungen, während rückläufige Produkte strategische Anpassungen oder Auslaufentscheidungen nahelegen.
4. Die Materialbedarfsprognose ermöglicht einen Übergang von reaktiver zu proaktiver Beschaffung, reduziert Lagerkosten und minimiert Lieferkettenrisiken durch datenbasierte Planung.
5. Die cloudnative Architektur mit MLflow-Orchestrierung gewährleistet Reproduzierbarkeit und Skalierbarkeit und bietet eine robuste Grundlage für Erweiterungen auf weitere Produktlinien, Märkte und Optimierungsszenarien in Echtzeit.Zukünftige Erweiterungen
Die aktuelle Batch-Prognoselösung kann zu einer Echtzeit-Optimierungsplattform weiterentwickelt werden, indem externe Einflussfaktoren wie Wirtschaftsindikatoren, Wetterdaten oder Wettbewerberpreise integriert und Streaming-Pipelines für Live-Bestandsupdates implementiert werden. Automatisiertes Modell-Retraining bei Daten-Drift könnte die Prognosequalität langfristig sichern. Darüber hinaus könnten API-Endpunkte Prognosen direkt in Unternehmenssysteme (ERP, CRM) integrieren. Langfristig unterstützt die Infrastruktur KI-gestützte Entscheidungsautomatisierung in Bereichen wie Produktionsplanung, dynamische Preisgestaltung, Predictive Maintenance sowie Nachhaltigkeitskennzahlen entlang der gesamten Lieferkette.
Interactive 3D Rotary Calciner Simulation for Process Engineering Education
Projektübersicht
Dieses Projekt wurde in Zusammenarbeit mit dem Institut für Verfahrenstechnik der Otto-von-Guericke-Universität Magdeburg (OvGU) entwickelt. Ziel war die Erstellung einer interaktiven 3D-Visualisierungsanwendung für die verfahrenstechnische Ausbildung, welche den universitären Pilotanlagen-Drehrohrofen digital nachbildet. Studierende erhalten dadurch die Möglichkeit, komplexe Industrieanlagen virtuell zu erkunden und den Kalzinierungsprozess durch immersive digitale Interaktion besser zu verstehen.Problemstellung
1. Wie können komplexe Industrieanlagen für Studierende zugänglich gemacht werden, wenn der physische Zugang zu Pilotanlagen eingeschränkt ist und klassische Vorlesungen kaum praktische Erfahrungen bieten?
2. Welcher Detaillierungsgrad und welche Interaktivität sind erforderlich, um sowohl strukturelle Komponenten als auch betriebliche Abläufe eines Drehrohrofens verständlich zu vermitteln?
3. Wie kann der Kalzinierungsprozess dynamisch visualisiert werden, sodass Materialbewegungen, thermische Zersetzungsphasen und Komponenteninteraktionen in Echtzeit dargestellt werden?Vorgehensweise und Methodik
1. Anforderungsanalyse und technische Spezifikationen
- Durchführung von Vor-Ort-Besuchen an der Pilotanlage der OvGU mit detaillierten Vermessungen und fotografischer Dokumentation.
- Dokumentation der technischen Spezifikationen des Drehrohrofens, Analyse des thermischen Zersetzungsprozesses sowie Berechnung relevanter Simulationsparameter.2. 3D-Modellierung und Asset-Erstellung
- Erstellung präziser Komponentenmodelle in SolidWorks für komplexe mechanische Bauteile (Motor, Kettenantrieb, Zahnkranz mit 33 Zähnen).
- Entwicklung visueller Modelle in Blender für Trommelstruktur, Stützrollen, Heizspiralen und Steuerungssysteme.
- Export der Modelle im .fbx-Format zur Integration in Unity unter Sicherstellung korrekter Skalierung und Texturzuweisung.3. Entwicklung der Unity-Anwendung
- Implementierung einer Entity-Component-System (ECS)-Architektur zur Gewährleistung modularer und skalierbarer Code-Strukturen.
- Entwicklung zentraler Verwaltungsklassen: DialogueManager (22 geführte Szenen), AnimationManager (Partikelphysik), AudioManager (synchronisierte Sprachführung).
- Realisierung zweier Interaktionsmodi: Geführter Lernpfad mit narrativer Begleitung sowie freie 3D-Erkundung mit Maus- und Slider-Steuerung (Zoom, Rotation).
- Implementierung eines ButtonControlScript zur konsistenten Navigation (Home-, Weiter-, Zurück- und Überspringen-Buttons in allen Szenen).4. Physikbasierte Simulation
- Programmierung einer realistischen Trommelrotation synchronisiert mit Motor- und Zahnkranzbewegung.
- Implementierung von Gravitation und Kollisionsphysik zur authentischen Simulation der Materialbewegung im rotierenden Ofen.5. Interaktive Lernfunktionen
- Komponentenerklärungsmodus: Hervorhebung einzelner Bauteile mit technischen Spezifikationen und didaktischen Erläuterungen.
- Simulationsmodus: Darstellung des vollständigen Betriebszyklus mit Materialzufuhr, Trommelrotation (RPM-gesteuert), Aktivierung der Beheizung und Partikelbewegung.6. Softwareentwicklungsprozess
- Anwendung agiler Methoden mit iterativer Entwicklung, regelmäßigen Feedback-Sitzungen mit Betreuenden und kontinuierlicher Optimierung.
- Durchführung von Usability-Tests mit Studierenden der Ingenieurwissenschaften zur Validierung der didaktischen Wirksamkeit und Benutzerfreundlichkeit.Zentrale Erkenntnisse
- Interdisziplinäre Zusammenarbeit zwischen Informatik und Verfahrenstechnik ermöglicht die Entwicklung effektiver Lehrwerkzeuge durch Kombination von Modellierungsexpertise und prozesstechnischem Fachwissen.
- Duale Interaktionskonzepte (geführtes Lernen vs. explorative Erkundung) berücksichtigen unterschiedliche Lernbedürfnisse und unterstützen sowohl strukturierte Lehrformate als auch selbstgesteuertes Lernen.
- Entwurfsmuster (Singleton, ECS, Decorator) gewährleisten Wartbarkeit und Erweiterbarkeit der Anwendung, wodurch zukünftige Ergänzungen von Komponenten oder Prozessen erleichtert werden.
- 3D-Visualisierung überbrückt die Lücke zwischen Theorie und Praxis in der Ingenieurausbildung, indem komplexe Anlagenabläufe bereits vor dem realen Industrieeinsatz nachvollziehbar gemacht werden.Zukünftige Erweiterungen
Die aktuelle Anwendung konzentriert sich auf die chargenweise Kalzinierung von Aluminiumhydroxid. Künftige Erweiterungen könnten variable Prozessparameter ermöglichen, sodass Nutzer Temperaturprofile, Drehzahlen und Materialeigenschaften anpassen und unterschiedliche Kalzinierungsergebnisse beobachten können. Eine Erweiterung auf weitere Materialien wie Kalkstein, Magnesit oder Petrolkoks mit materialspezifischem thermischem Verhalten ist ebenfalls denkbar.
Die Integration von Echtzeit-Datenvisualisierungen (Temperaturverläufe, Feuchtigkeitskurven, Energieverbrauchskennzahlen) würde das quantitative Lernen stärken. Zudem könnte eine VR-/AR-Implementierung immersive Lernerfahrungen ermöglichen, während integrierte Bewertungsmodule mit Quiz- und Simulationsaufgaben Lernfortschritte messen und automatisiertes Feedback für selbstgesteuertes Lernen bereitstellen.
Sales and Profit Dashboard in Power BI
Projektübersicht
Dieses Projekt wurde im Rahmen der Lehrveranstaltung „Data Visualization“ der Visualization Group an der Otto-von-Guericke-Universität Magdeburg entwickelt. Es präsentiert ein interaktives Power-BI-Dashboard auf Basis eines mehrjährigen US-Superstore-Datensatzes zu Umsatz und Gewinn, der von Kaggle bezogen wurde. Die Anwendung ermöglicht die Analyse der Profitabilität nach Region, Kundensegment, Produktkategorie und Zeitverlauf mithilfe klarer Visualisierungen und eines intuitiven, explorativen Layouts. Der Fokus liegt auf einer fortgeschrittenen, interaktiven Berichterstattung, die Leistungskennzahlen und geschäftliche Treiber transparent macht.Problemstellung
1. Wie lassen sich Einzelhandelsdaten eines Superstores so visualisieren, dass Umsatz- und Gewinnpotenziale über Kundengruppen, Produktkategorien und geografische Regionen hinweg klar erkennbar werden?
2. Welche Gewinnmuster zeigen sich im Zeitverlauf, und wie unterscheiden sie sich zwischen Regionen und Produktunterkategorien?
3. Welche Kundensegmente tragen am stärksten zur Profitabilität bei, und welche Kategorien weisen eine nachhaltige Umsatzentwicklung auf?
4. Wie kann ein interaktives Dashboard eine schnelle, Self-Service-Analyse komplexer, mehrdimensionaler Verkaufsdaten zur Unterstützung fundierter Entscheidungen ermöglichen?Methodik und Vorgehen
Datensatz:
Der ausgewählte Kaggle-Datensatz bildet realistische Einzelhandelstransaktionen ab und eignet sich für eine fundierte betriebswirtschaftliche Analyse und Visualisierung mit folgenden Merkmalen:
- Rund 9.994 Datensätze aus den Jahren 2016–2019.
- Alle Kennzahlen sind in USD angegeben.
- Zentrale Felder umfassen Kundensegmente (Consumer, Corporate, Home Office), Produktkategorien und -unterkategorien (Furniture, Office Supplies, Technology), Versandart, Bestelldatum, geografische Attribute (50 US-Bundesstaaten, gruppiert in vier Regionen), Umsatz, Menge und Gewinn.1) Datenaufbereitung und -bereinigung
- Import des Datensatzes sowie Prüfung von Struktur, Datentypen und Felddefinitionen.
- Durchführung von Qualitätsprüfungen hinsichtlich Datumsbereichen, Konsistenz kategorialer Variablen sowie Plausibilität von Umsatz- und Gewinnwerten zur Sicherstellung verlässlicher Berichte.2) Dashboard-Design in Power BI
- Erstellung verschiedener Visualisierungen zur Analyse der Performance aus unterschiedlichen Perspektiven, darunter:
- Kreisdiagramme zur Darstellung des regionalen Gewinnanteils.
- Donut-Diagramme zur Gewinnverteilung nach Kundensegment und Produktkategorie.
- Balkendiagramme zum Vergleich der Gewinne zwischen Produktunterkategorien.
- Liniendiagramme zur Analyse von Gewinntrends nach Jahr bzw. Quartal.
- Tabellen zur detaillierten Darstellung von Umsatz- und Gewinnkennzahlen.
- Slicer (z. B. nach Bundesstaat) sowie KPI-Karten zur schnellen Filterung und zusammenfassenden Leistungsbewertung.
Das Berichtskonzept unterstützt Drill-Down-Funktionen und Cross-Filtering für vertiefende Analysen.3) Interaktivität und Benutzererfahrung
- Ermöglichung interaktiver Analysen durch Slicer, Hover-Tooltips und visuelles Cross-Highlighting.
- Strukturierte Layout-Gestaltung zur intuitiven Navigation vom KPI-Überblick hin zu detaillierten Auswertungen.Zentrale Erkenntnisse
1. Das Dashboard bietet eine konsolidierte Sicht auf Umsatz und Gewinn über Zeit, Regionen und Produktstrukturen hinweg und unterstützt datenbasierte.
2. Entscheidungen.
Unterschiedliche Visualisierungsperspektiven ermöglichen die Identifikation leistungsstarker Regionen und Kategorien sowie potenziell unrentabler Unterkategorien.
3. Die Kundensegmentanalyse zeigt, wie verschiedene Käufergruppen unterschiedlich zur Profitabilität beitragen.
4. Interaktive Funktionen (Filter und Drill-Down) fördern explorative Analysen und erlauben individuelle Auswertungen ohne Anpassung des Berichts.Anleitung zur Nutzung des Dashboards
1. Laden Sie die Power-BI-Datei (.pbix) aus dem GitHub-Repository herunter.
2. Öffnen Sie die Datei mit Power BI Desktop (kostenlose Microsoft-Anwendung).
3. Nutzen Sie Slicer und interaktive Visualisierungen, um Umsatz und Gewinn nach Bundesstaaten, Regionen, Segmenten und Produktlinien zu analysieren.
AI-Powered Test Automation Agent
Projektübersicht
Dieses Projekt implementiert ein natürlichsprachlich gesteuertes System, mit dem strukturierte Testfälle und ausführbare Playwright-Automatisierungsskripte aus einfachen englischen Beschreibungen generiert werden können. Durch die Angabe einer Ziel-URL und einer kurzen Testbeschreibung analysiert die Pipeline automatisch die Anwendung, identifiziert testbare Verhaltensweisen und erstellt sofort einsatzbereite TypeScript-Testskripte mit einem Self-Healing-Mechanismus, der fehlgeschlagene Tests automatisch zu korrigieren versucht, bevor Ergebnisse ausgegeben werden.Problemstellung
Die Erstellung automatisierter UI-Tests gehört zu den zeitaufwendigsten und kompetenzabhängigsten Aufgaben im Software-Qualitätsmanagement:
1. Die Überführung von Feature-Anforderungen in strukturierte Testfälle erfordert sowohl Fachwissen als auch QA-Expertise und stellt damit einen Engpass für Entwickler und Nicht-QA-Teammitglieder dar.
2. Selbst bei generierten Testfällen erfordert deren Wartung und Anpassung bei Weiterentwicklung der Anwendung weiterhin manuellen Aufwand sowie ein Verständnis der zugrunde liegenden Testlogik.
3. Die Erstellung und Fehlersuche in Playwright-Skripten setzt Kenntnisse in Browser-Automatisierungs-APIs, TypeScript und asynchronen Programmiermustern voraus – technische Hürden, die die Testabdeckung verlangsamen und Fehlerbehebungen verzögern.Lösung & Implementierung
Entwicklung einer Full-Stack-Agentenapplikation mit einem zweistufigen Generierungsworkflow, basierend auf einer crewAI-Multi-Agenten-Pipeline:- Testfallgenerierung (Schritt 1): Der Nutzer gibt Ziel-URL, Testnamen und Beschreibung ein. Ein dedizierter Explorationsagent analysiert die Live-Anwendung mithilfe von Playwright MCP, um Struktur und Interaktionen zu erfassen. Ein Testfall-Generator-Agent erstellt daraufhin strukturierte, verständlich formulierte Testfälle, die in der Benutzeroberfläche zur Überprüfung angezeigt werden.- Skriptgenerierung & Ausführung (Schritt 2): Der Nutzer wählt die zu automatisierenden Testfälle aus. Ein Skriptgenerierungsagent erzeugt eine TypeScript-Playwright-Spezifikation für die ausgewählten Szenarien. Ein Ausführungsagent startet die Tests und löst im Fehlerfall bis zu drei automatisierte Korrekturversuche mittels LLM-gestützter Selbstkorrektur aus, bevor das finale Ergebnis ausgegeben wird.- Artefakt-Downloads: Nach jedem Durchlauf können Playwright-Skripte, Testfälle im Markdown- und JSON-Format, Explorationsdaten sowie ein KI-generierter Testbericht heruntergeladen werden. Dies ermöglicht die Integration in bestehende CI/CD-Pipelines oder eine weiterführende manuelle Optimierung.Das Backend basiert auf FastAPI mit Server-Sent Events (SSE) für Echtzeit-Log-Streaming. Das Frontend wurde mit React, Vite und Tailwind CSS umgesetzt. Die gesamte Agentenorchestrierung erfolgt über crewAI, mit OpenAI als LLM-Anbieter.Mehrwert & Nutzen1. Senkt die Einstiegshürde für UI-Testautomatisierung, indem browserbasierte Tests unabhängig von Playwright- oder TypeScript-Kenntnissen direkt aus natürlicher Sprache generiert und ausgeführt werden können.
2. Die Self-Healing-Ausführungsschleife reduziert manuelle Debugging-Zyklen und erhöht die Testzuverlässigkeit ohne zusätzlichen Entwickleraufwand.
3. Strukturierte Artefakte (Skripte, Berichte, JSON-Testfälle) gewährleisten Kompatibilität mit bestehenden QA-Prozessen und Dokumentationsstandards.Verwendung der Anwendung
1. Öffnen Sie das Projekt-Repository und folgen Sie der README-Anleitung zur Einrichtung und zum Start der Anwendung.
2. Geben Sie Ziel-URL, Testnamen und Beschreibung ein und klicken Sie auf „Testfälle generieren“.
3. Überprüfen Sie die generierten Testfälle, wählen Sie die gewünschten Szenarien aus und klicken Sie auf „Skript generieren“.
4. Verfolgen Sie den Live-Fortschritt im Statusbereich (technische Logs können optional eingeblendet werden).
5. Laden Sie das Playwright-Skript, die Testfalldateien und den Testbericht im Artefaktbereich herunter.Zukünftige Erweiterungen
Die Agentenpipeline kann erweitert werden, um zusätzliche Testframeworks wie Cypress oder Selenium zu unterstützen, mehrseitige Abläufe mit zustandsübergreifender Verfolgung abzudecken sowie CI/CD-Integrationen (z. B. GitHub Actions) für vollständig automatisierte Regressionstests zu ermöglichen. Darüber hinaus könnten visuelle Regressionstests und Accessibility-Prüfungen als spezialisierte Agenten innerhalb des crewAI-Workflows ergänzt werden.